
Remember to stretch
Stretching is an important part of any keep fit regime, but what about when it comes to deploying enterprise analytics platforms?
This blog post introduces the concept of a “Stretch Cluster” for running your analytics workloads.
Use this approach to:
- Reduce RPO and RTO to zero
- Add/improve High Availability (HA)
- Improve uptime and SLA adherence
- Enable regular patching/maintenance with zero downtime
Faced with increasing scrutiny from regulators and growing dependency from core business units, Enterprise Analytics platforms are often early in line to be migrated to the cloud to leverage its many benefits. However, under certain circumstances, making the move to someone else’s datacentre isn’t palatable or (easily) possible.
Possible reasons preventing migration to the cloud:
- Data gravity – large footprint source/target systems remaining on premise with no immediate schedule for migration. Splitting source/target systems between on premise and cloud will incur large data egress charges. When usage is skewed towards ad-hoc development this becomes particularly problematic as costs cannot be reliably forecast/capped.
- No clearly defined cloud strategy – Without a clearly defined long term cloud strategy and a typical 3-5 year lifecycle for an analytics platform, making a long term decision without a fundamental strategy in place is a big risk. In most cases it pays to be conservative and to maximise existing on-premise infrastructure agreements
- Unclear ROI – the financial benefits for moving to cloud are not clear and/or cannot be accurately forecast to align with budgetary constraints. In some cases, remaining on premise represents better value for money.
Staying On-Premise
If cloud deployment is not feasible – how can we leverage technology to bring cloud-like capabilities to an on-premise analytics deployment?
The table below describes desirable features, their purpose and examples of the technologies which provide them:
| Feature | Purpose | Example |
| Synchronous storage replication | Replication of data between 2 (or more) sites | Hitachi GAD Spectrum Scale Replication |
| Clustered filesystem | High performance parallel access (reads and writes) to data across multiple nodes/machines | IBM Spectrum Scale (GPFS) |
| Virtualisation | High availability, efficiency, scaling | VMWare |
| Workload management | Control and placement of cluster and user jobs/processes | Spectrum LSF |
| Service orchestration | Control and placement of cluster and services | LSF EGO |
Storage is the key technology which underpins a stretch cluster and enables an active/active Stretch Cluster configuration.
Active/Active Stretch Cluster
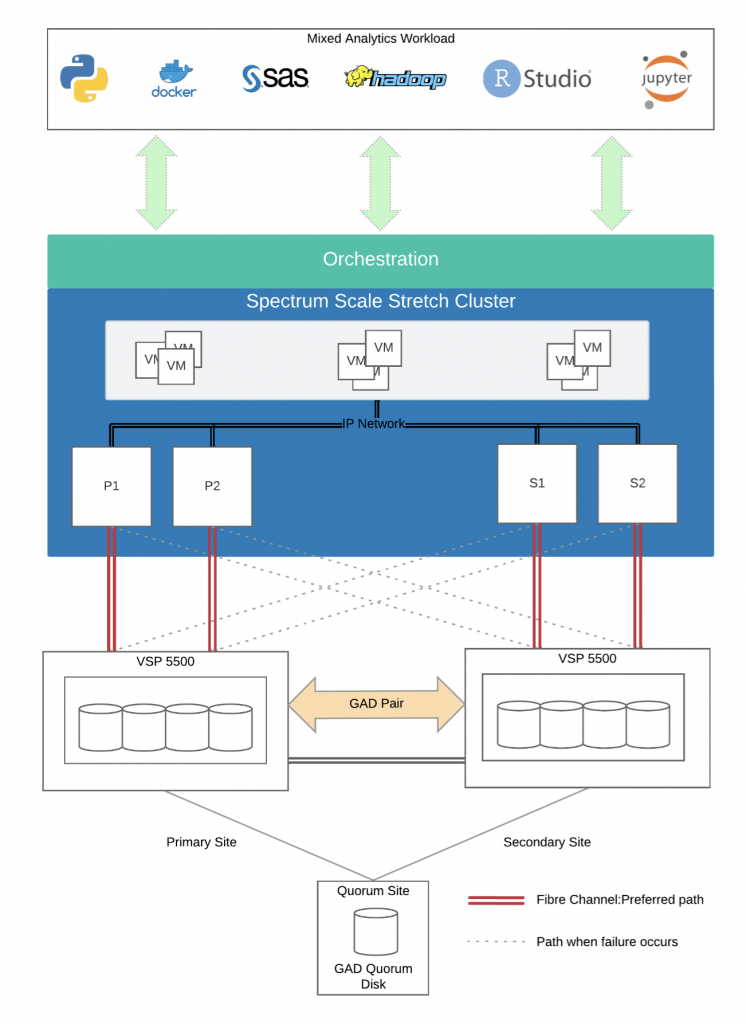
A stretch cluster is a single entity, “stretched” between 2 geographically separate sites. In cloud parlance, this would be 2 availability zones. In terms of deployment, configuration, administration and licensing, a stretch cluster is a single deployment. A combination of technologies makes this configuration possible – however the most import is: synchronous storage replication.
Storage volumes are configured on a SAN at each site and configured into a “GAD pair” which enables synchronous replication.
Each volume pair is presented to each of the servers over multiple fibre channel connections and aggregated using multipathd
Spectrum Scale NSDs are created by mapping each multipath device to an NSD which are grouped together to form a GPFS filesystem
Local path optimisation ensures reads/writes are performed from/to the closest SAN (during normal operation)
In the event of path/SAN failure – the secondary/backup path is used. This incurs a performance penalty but ensures continuity of service.
Orchestration ensures placement of jobs/processes to an appropriate node in the cluster.
Nodes can be closed to allow rolling maintenance/upgrades without interuption of service across the cluster
Hitachi LUN snapshotting enables quick recovery of storage volumes to help reduce outage windows (RTO) in the event of issues.
Synchronous Data Replication
To ensure data availability across 2 sites – some form of synchronous data replication is required, this may also be referred to as data mirroring. Each vendor will have their own technologies/approaches to this, the essential feature is that the technology must ensure synchronous replication/mirroring; there cannot be any lag or delay in the replication (otherwise known as asynchronous) otherwise the cluster cannot run in an active/active configuration and in effect all you have is an active/passive setup. Here we discuss the 2 synchronous data replication/mirroring options. Technologies available will depend on your estate and the distance between each location the stretch cluster is configured across.
Storage Based Replication: Hitachi GAD
The storage sub system is responsible for handling the replication using dedicated, redundant high bandwidth cross site links. Using GAD, a virtual storage machine is configured in the primary and secondary storage systems using the actual information of the primary storage system, and the global-active device primary and secondary volumes are assigned the same virtual LDEV number in the virtual storage machine. This enables the host to see the pair volumes as a single volume on a single storage system, and both volumes receive the same data from the host. Local path optimisation ensures that I/O is handled on the SAN local to the node during normal operation. In the event of path or storage array failure, the (secondary) remote path is used which incurs a performance penalty due to the remote writes, however it ensures service continuity and therefore the ability to sustain uptime.
Hitachi Global-active Device (GAD) enables synchronous remote copies of data volumes which provide the following benefits:
- Continuous server I/O when a failure prevents access to a data volume
- Server failover and failback without storage impact
- Load balancing through migration of virtual storage machines without storage impact
An example GAD enabled configuration is below. A third, geographically separate quorum site is required to act as a heartbeat for the GAD pair. Communication failure between systems results in a series of checks with the quorum disk to identify the problem.
GPFS replication
By configuring data volumes into 2 failure groups (1 per site) and enabling 2 data replicas – GPFS is responsible for ensuring blocks are replicated between sites. Nodes at each site are connected to a site-specific SAN and GPFS assigns block replicas to the distinct failure groups (i.e. the data is copied/mirrored to a distinct set of devices at each site) – this ensures nodes at the primary and secondary sites see the same data. The downside to using this method is the replication is managed and processed by the server nodes, adding overhead. Replication is (usually) carried out over the LAN which incurs performance penalties vs using storage-based replication which uses a dedicated fabric. Data replication also doubles (or triples) the data footprint managed by GPFS – which increases licensing costs significantly due to GPFS running under a capacity based license.
Whichever replication option is selected, what this means in simple terms, is that your data is available at 2 sites simultaneously, allowing services and workload to migrate/move between nodes while retaining access to the same data. Workload can also be run in parallel across multiple nodes regardless of location.